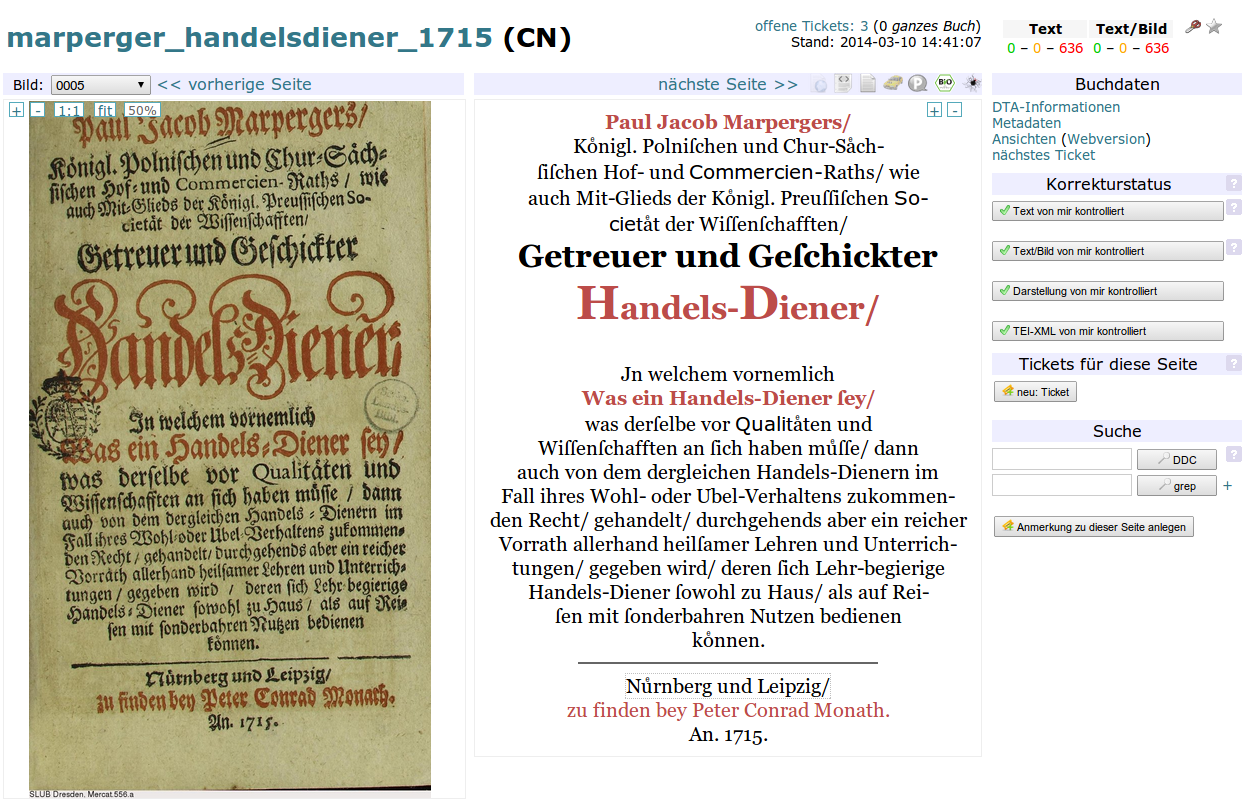
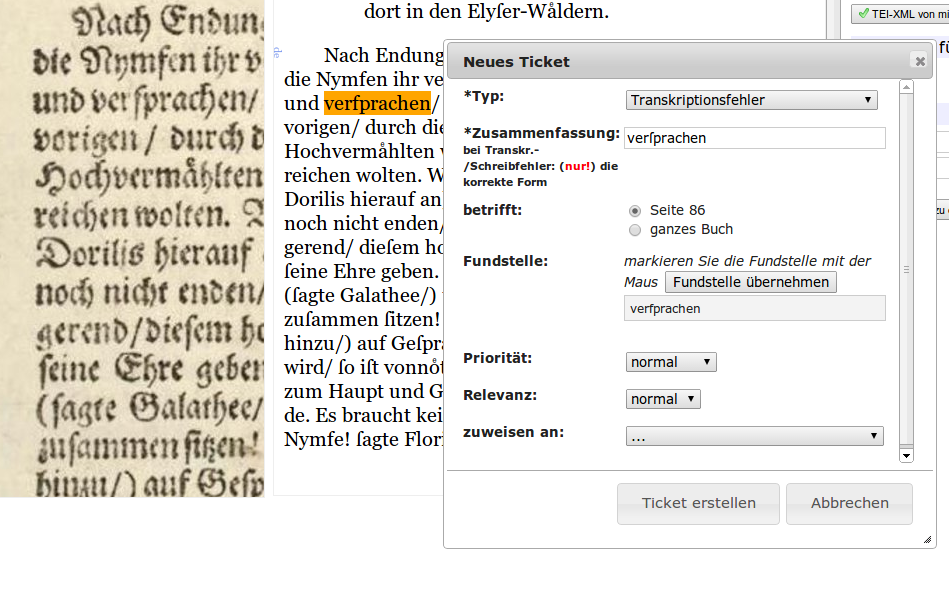
Kollaborative Qualitätssicherung im Deutschen Textarchiv
DTAQ (Deutsches Textarchiv – Qualitätssicherung) ist eine webbasierte Anwendung, um in XML/TEI-annotierten Textdigitalisaten verschiedene Arten von Fehlern zu finden, zu kategorisieren und zu korrigieren. Die Oberfläche von DTAQ ist durch jeden Nutzer individuell anpassbar, so dass verschiedene Ansichten der Quelldigitalisate und Texttranskriptionen einstellbar sind.
DTAQ ist nach der Registrierung frei für jeden nutzbar.